Example:
@a_decorator_func
def main_func()
do_somethingIt means main_func = a_decorator_fuc(main_func).
We should return a function in a_decorator_func.
Example:
@a_decorator_func
def main_func()
do_somethingIt means main_func = a_decorator_fuc(main_func).
We should return a function in a_decorator_func.
This a popular technique in data science. Its goal is reduce dimension of an original space form M dimensions to N ones where M >> N.
Predefine number of clusters N.
Illustrated by this example. There are 4 main points, around them we create random points.

To do kmeans, we choose randomly N points from the given points as initial N cluster centers. Then we update label for all given points based on the fact that which center is the nearest to a point. After updating labels for the all given points, we redefine centers for N clusters as mean point of labelled points.
We repeat the task until N cluster centers are unchanged – or SSTC (sum of squared of distances from points to their cluster centers) get local minimum.
def kmeans_init_centers(df, n_cluster):
"""
Pick randomly n centers of n clusters from df (coordinates of points)
"""
rand_row_index = np.random.choice(df.shape[0], n_cluster, replace=False)
return df.iloc[rand_row_index][["x", "y"]].reset_index().drop(columns="index")
def display_cluster(df_points, df_cluster, title, label_col="main_point"):
"""
Plot
"""
fig, axes = plt.subplots(1,1, figsize=(10,5))
for key, value in main_points.items():
df = df_points[df_points[label_col]==key]
axes.scatter(df["x"], df["y"], marker=value["marker"], color=value["color"], label=key, s=50)
if df_cluster is not None:
for key, value in main_points.items():
pt = df_cluster.iloc[key]
axes.scatter(pt["x"], pt["y"], marker=value["marker"], color="navy", label=key, s=200)
# variance
variance = kmeans_loss_func(df_points, np.array(df_points[label_col]), df_cluster)
fig.legend()
fig.suptitle(f"{title} -> SSTC={variance}")
fig.show();
def kmeans_assign_labels(df_points, df_centers):
"""
Assign label to list of points
"""
D = cdist(df_points[["x", "y"]], df_centers)
return np.argmin(D, axis=1)
def kmeans_update_centers(df_points, labels, n_cluster):
"""
Create new centers from the latest label assignment to points
"""
centers = []
for k in range(n_cluster):
df_k = df_points.iloc[labels==k]
centers.append({"x":df_k["x"].mean(), "y":df_k["y"].mean()})
# print(centers)
centers = pd.DataFrame(centers)
return centers
def kmeans_loss_func(df_points, labels, df_centers):
variance = 0
for k in range(n_cluster):
df_k = df_points.iloc[labels==k]
dis_arr = cdist(df_k[["x", "y"]], df_centers.iloc[[k]])
variance += np.sum(np.power(dis_arr,2.0))
return variance
def has_coverged(centers, new_centers, tolerance=1e-9):
"""
Check if center == new_centers
"""
if np.sqrt(np.power(centers-new_centers, 2.0).sum(axis=1)).sum() < tolerance:
return True
return False
def my_kmeans(df_points, n_cluster):
"""
Kmeans algorithm
"""
centers = [kmeans_init_centers(df_points, n_cluster)]
labels = []
loss_functions = []
it = 1
display_cluster(df_points, centers[-1], title="Initial")
while True:
# assign label for according to the current centers
labels.append(kmeans_assign_labels(df_points, centers[-1]))
df_points["tmp_label"] = labels[-1]
display_cluster(df_points, centers[-1], title=f"Label from centers of it={it}", label_col="tmp_label")
new_centers = kmeans_update_centers(df_points, labels[-1], n_cluster)
display_cluster(df_points, new_centers, title=f"Update new centers of it={it}", label_col="tmp_label")
loss_functions.append(kmeans_loss_func(df_points, labels[-1], new_centers))
if has_coverged(centers[-1], new_centers):
loss_functions.append(kmeans_loss_func(df_points, labels[-1], new_centers))
break
centers.append(new_centers)
it += 1
return (centers, labels, loss_functions, it)
Centres are selected, labels are assigned to points, and centres are updated based on the labelled points. The sum of squares total count (SSTC) decreased from 4183 to 332, and then to 290.


This loss function depends on initial centers.
In this example, in a case it changes:

In another initial centers set, it changes:

With sklearn, we also can conduct kmeans quite easily:
from sklearn.cluster import KMeans
np_points = df_points[["x", "y"]].to_numpy()
s_kmeans = KMeans(n_clusters=n_cluster, random_state=0).fit(np_points)
print("Centers found by scikit-learn:")
s_kmeans_center_points = pd.DataFrame(s_kmeans.cluster_centers_).rename(columns={0:"x", 1:"y"})
print(s_kmeans_center_points)
print(f"SSTC = {s_kmeans.inertia_}")
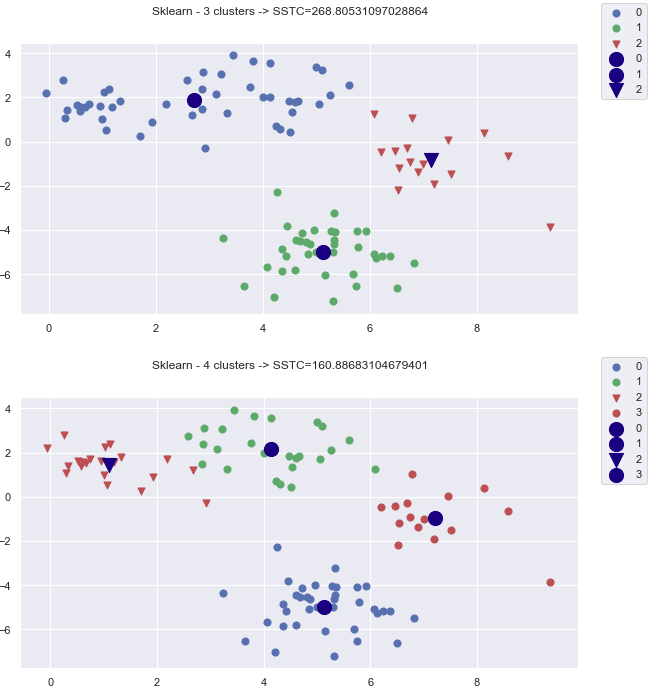
s_pred_label = s_kmeans.predict(np_points)Comparing approaches, sometime we can see that kmeans suggest better clustering (based on SSTC) than we create main points and their random around ones.


Result from sklearn seems good!
We implement elbow method to check how loss function changes when number of cluster varies. We tested with n_cluster from 3 to 25. It shows that “elbow” point is 4 – that concedes with original design of the points ( 4 main points and random points).

Kmeans cluster for n_cluster = 3 -> 8:


sqlite3 is a light module for database manager in python while json is dedicated for json format.
CREATE TABLE table_name(col1 INTEGER PRIMARY KEY, col2 TEXT NOT NULL, col3 REAL)
NULL is equivalent to None in Python.
datatype in sqlite3: NULL, INTEGER, REAL, TEXT, BLOB.
Result of SELECT query SQLITE database inside Python, will return None for NULL value. Other NOT NULL values are fetched in types declared in table creation.
The following code snippet elaborates above notes:
import sqlite3
conn = sqlite3.connect('test.db', 1)
cursor = conn.cursor()
# create table
sql_query = ''' CREATE TABLE IF NOT EXISTS table1 (id INTEGER PRIMARY KEY, name TEXT NOT NULL, age REAL) '''
cursor.execute(sql_query)
conn.commit()
# insert table
sql_query = ''' INSERT OR IGNORE INTO table1 (id, name, age) VALUES(?, ?, ?) '''
values = [(1, 'Ram', None), (2, 'Thao', 28), (3, 'Truong', 33)]
for val_tuple in values:
cursor.execute(sql_query, val_tuple)
conn.commit()
# query table
sql_query = ''' SELECT id, name, age FROM table1 '''
cursor.execute(sql_query)
records = cursor.fetchall()
for record in records:
print [(type(item), item) for item in record]
Output:
[(<type 'int'>, 1), (<type 'unicode'>, u'Ram'), (<type 'NoneType'>, None)]
[(<type 'int'>, 2), (<type 'unicode'>, u'Thao'), (<type 'float'>, 28.0)]
[(<type 'int'>, 3), (<type 'unicode'>, u'Truong'), (<type 'float'>, 33.0)]
For json, dumps and loads are most used as following.
Note: null of json == None of Python
Code that elaborates use of json in Python:
import json
info = {'group1': [{'name' : 'td1', 'age' : 20}, {'name' : 'td2', 'age' : 15}],
'group2': [{'name' : 'td3', 'age' : None}, {'name' : 'td4', 'age' : 20}]
}
# dump to json
print 'Create json file'
with open('example.json', 'w') as fopen:
fopen.write(json.dumps(info))
# show file content
print 'Show saved json file'
with open('example.json') as fopen:
print fopen.read()
# load
print 'Load json file to Python dict'
with open('example.json') as fopen:
print json.load(fopen)
OUTPUT:
Create json file
Show saved json file
{"group1": [{"age": 20, "name": "td1"}, {"age": 15, "name": "td2"}], "group2": [{"age": null, "name": "td3"}, {"age": 20, "name": "td4"}]}
Load json file to Python dict
{u'group1': [{u'age': 20, u'name': u'td1'}, {u'age': 15, u'name': u'td2'}], u'group2': [{u'age': None, u'name': u'td3'}, {u'age': 20, u'name': u'td4'}]}
I’ve been told for a long time that GIT is a great tool for developers in managing software building.
Since I started my career as a quantitative researcher, I have involved much more into programming on C++ or recently Python. Scripts have been increasing in term of size and complexity. As a result, I decided to learn about GIT.
There are lots things inside it. Reading some tutorials, I found out the best way to master it is try to implement into a small project and practice basis commands.
There are some important commands:
Normal repository workflow: initialization >> create/modify files >> add files to staged >> commit files >> view commit log
cd projA
git init # Initialize git inside projA
git status [-s] # Get the latest status of repository, files
git add file_1 file_2 # Add given files to staged (index)
git commit -m 'Something to say' # Commit things in stage
git log # Get log of repository process
git log --oneline # Get log in format of one lines
git log branch_name # Log commit the the given branch Normal clone from a repository: mkdir target_dir >> cd target_dir >> clone
git clone path_to_projA .Repository workflow in different branches (parallel modification):
git branch new_branch # create new_branch
git checkout new_branch # change to work on new_branch
git checkout master # back to master branch
git merge new_branch # merge master and new_branch while on master branchBack to specified commit:
git checkout commit_idCorrect the last commit:
edit files # correct files
git add files # to stage
git commit --amend # comment of the last commit is showed in an editor , allow we to edit and commit Get last update from repository (where it was cloned before):
# pull from master (default branch)
git pull origin master
# pull from a specific branch
git pull origin a_given_branch
# get update of a specific file
git fetch origin a_given_branch
git checkout FETCH_HEAD fileTo clone specific files in a new directory:
# initialization git
git init
# add origin
git remote add origin path_to_repo
# fetch
git fetch origin master
# checkout FETCH_HEAD
git checkout FETCH_HEAD file1 file2
Some classes are friend to other classes, it means they can access even private data member of other class. Let’s exam the following script to figure out the concept.
// Example program
#include
#include
using namespace std;
class Coord;
class Display{
public:
Display(){}
void show(const Coord& t);
};
class Display2;
class Coord{
private:
double m_dx, m_dy;
public:
Coord(double dx = .0, double dy = .0){
m_dx = dx;
m_dy = dy;
}
friend double getDistance(const Coord& t);
friend Coord addPoint(const Coord& t1, const Coord& t2);
friend Display2;
friend void Display::show(const Coord& t);
};
class Display2{
public:
Display2(){}
void show(const Coord& t){
printf("[ %3.1f , %3.1f ] \n",t.m_dx,t.m_dy);
}
};
double getDistance(const Coord& t){
return pow(t.m_dx*t.m_dx + t.m_dy*t.m_dy,.5);
}
Coord addPoint(const Coord& t1, const Coord& t2){
return Coord(t1.m_dx + t2.m_dx, t1.m_dy + t2.m_dy);
}
void Display::show(const Coord& t){
printf("{ %3.1f , %3.1f } \n",t.m_dx,t.m_dy);
}
int main()
{
Coord t1(3,4), t2(6,8);
printf("%3.1f\n", getDistance(t1));
printf("%3.1f\n", getDistance(addPoint(t1,t2)));
Display2 d1;
Display d;
d1.show(t1);
d.show(t1);
}<span id="mce_SELREST_start" style="overflow:hidden;line-height:0;"></span>
This example tells a quite completed story about friend classes.
Class Display2 is a friend class of Coord while member function Display::show() is a friend function of Coord.
Note: class Display declares a function that has an argument of class Coord, therefore before its definition we need to declare Coord. However the function show that access data members of Coord is only defined after Coord definition.
This a function that is NOT a function member of a CLASS but has a right to access all data member of it. For example, the following friend functions: one just prints data member and another add two objects of a class.
// Example program
#include <iostream>
using namespace std;
class Trial{
private:
int m_a;
public:
Trial(int a=0){
m_a = a;
}
void setValue(int a){
m_a = a;
}
friend int getValue(const Trial& t){
return t.m_a;
}
friend Trial addT(const Trial& t1, const Trial& t2){
return Trial(t1.m_a + t2.m_a);
}
};
int main()
{
Trial t1(4), t2(5);
printf("%d\n", getValue(t1));
printf("%d\n", getValue(addT(t1,t2)));
}
As we can see , friend function can getValue can access private member data of class Trial.
Constructor is neccessary element of any classes. It’s basic stuff. However, there is a case when errors encountered and we find it difficult to debug. Here is one of them.
// Example program
#include
using namespace std;
class Trial{
private:
int m_a;
public:
Trial(int a){
m_a = a;
}
int getValue() const {
return m_a;
}
void setValue(int a){
m_a = a;
}
};
int main()
{
Trial t;
t.setValue(3);
printf("%d",t.getValue());
}
It will cause an error because when we create an object of class Trial without initialization list, it need a DEFAULT CONSTRUCTOR, but we forgot to define it. To solve this problem, there is very simple way. Here you are:
// Example program
#include <iostream>
using namespace std;
class Trial{
private:
int m_a;
public:
Trial(int a=0){
m_a = a;
}
int getValue() const {
return m_a;
}
void setValue(int a){
m_a = a;
}
};
int main()
{
Trial t;
t.setValue(3);
printf("%d",t.getValue());
}
#include <iostream>
using namespace std;
// ascending order
template<class T>
bool ascending(T first, T second){
return first<=second;
}
// descending order
template<class T>
bool descending(T first, T second){
return first>=second;
}
// swap two elements of a given array
template<class T>
void swap(T arr[],unsigned ii,unsigned jj){
T temp;
temp=arr[ii];
arr[ii]=arr[jj];
arr[jj]=temp;
}
// bubble sort
/*
The idea is: For a particular ii, compare it with all the next element, if there is any element that breaks out the expected order than swap positions
*/
template<class T>
void bubbleSort(T arr[],unsigned size,bool(*comparison)(T,T)){
for (unsigned ii=0;ii<size-1;++ii){
for (unsigned jj=ii+1;jj<size;++jj){
if (!comparison(arr[ii],arr[jj])) swap(arr,ii,jj);
}
}
}
// insertion sort
/*
The idea is: For a particular ii, compare it with the previous subarray
*/
template<class T>
void insertionSort(T arr[],unsigned size,bool(*comparison)(T,T)){
for(unsigned ii=0;ii<size;++ii){ unsigned jj=ii; while (jj>0){
if (!comparison(arr[jj-1],arr[jj])) swap(arr,jj-1,jj);
jj--;
}
}
}
// selection sort
/*
The idea is: For a particular ii, seek for the min(max) of the subarray after it, if the found element is different from ii, then swap
*/
template<class T>
void selectionSort(T arr[],unsigned size,bool(*comparison)(T,T)){
for(unsigned ii=0;ii<size-1;++ii){
unsigned iMin=ii;
for (unsigned jj=ii+1;jj<size;++jj){
if (!comparison(arr[iMin],arr[jj])) iMin=jj;
}
if (iMin!=ii) swap(arr,iMin,ii);
}
}
//merge sort
/*
The idea is: divide and conquer.
*/
// merge function
template<class T>
void merge(T arr[],unsigned start,unsigned mid,unsigned end){
unsigned ii(start),jj(mid+1),kk(0);
T temp[end-start+1];
while (ii<=mid && jj<=end){
if (arr[ii]<arr[jj]){
temp[kk]=arr[ii];
ii++;
}else{
temp[kk]=arr[jj];
jj++;
}
kk++;
}
if (ii<=mid){
for (unsigned tt=ii;tt<=mid;++tt,++kk){
temp[kk]=arr[tt];
}
}
if (jj<=end){
for(unsigned tt=jj;tt<=end;++tt,++kk){
temp[kk]=arr[tt];
}
}
for (unsigned tt=0;tt<kk;++tt){
arr[start+tt]=temp[tt];
}
}
// recursion function
template<class T>
void mergeSort(T arr[],unsigned start,unsigned end){
if (start<end){
unsigned mid=(start+end)/2;
mergeSort(arr,start,mid);
mergeSort(arr,mid+1,end);
merge(arr,start,mid,end);
}
}
// Shell sort
/*
The idea is: Develop from insertion sort and use gap to avoid moving too far
*/
template<class T>
void shellSort(T arr[],unsigned size){
for (unsigned gap=size/2;gap>0;gap/=2){
cout<<"ga="<<gap<<endl;
for (unsigned ii=gap;ii<size;++ii){
cout<<"ii="<<ii<<endl; T temp=arr[ii]; unsigned jj; for(jj=ii;jj>=gap && arr[jj-gap]>temp;jj-=gap){
cout<<"jj="<<jj<<endl;
arr[jj]=arr[jj-gap];
}
arr[jj]=temp;
}
}
}
LinkedList.h
#ifndef LINKEDLIST_H
#define LINKEDLIST_H
struct Link {
int num;
Link* next;
};
class LinkedList{
private:
Link *first,*last;
public:
LinkedList(); // default constructor
LinkedList(unsigned size,int uniformValue); // initialize a list with size element of uniformValue
LinkedList(int *start, int *end); // initialize a list from start to end (not included end)
void push_front(int value); // add new item to the front of the list
void push_back(int value); // add new item to the end of the list
int size(); // return the size of the list
void display(); // display content of the list
int operator [](unsigned index); // overloading operator []
int front(); // return the first element of the list
int back(); // return the last element of the list
};
#endif
LinkedList.cc
#include <iostream>
#include <climits>
#include "LinkedList.h"
using namespace std;
//default constructor
LinkedList::LinkedList():first(NULL),last(NULL){}
// initialize a list with size element of uniformValue
LinkedList::LinkedList(unsigned size,int uniformValue){
Link* arr=new Link[size];
for (unsigned ii=0;ii<size;++ii){
arr[ii].num=uniformValue;
if (ii<size-1) arr[ii].next=arr+ii+1;
else arr[ii].next=NULL;
}
first=arr;
last=arr+size-1;
}
// initialize a list from start to end (not included end)
LinkedList::LinkedList(int *start, int *end){
int size=end-start;
Link* arr=new Link[size];
for (unsigned ii=0;ii<size;++ii){
arr[ii].num=*(start+ii);
if (ii<size-1) arr[ii].next=arr+ii+1; else arr[ii].next=NULL; } first=arr; last=arr+size-1; } // add a new item to the front of the list void LinkedList::push_front(int value){ Link* pt=new Link; //create a new atom pt->num=value;
pt->next=first;
first=pt;
if (last==NULL) last=first; // if there is only one entity in the list so first=last
}
// add a new item to the back for the list
void LinkedList::push_back(int value){
Link* pt =new Link;
pt->num=value;
pt->next=NULL;
if (last==NULL) {
last=pt;
first=last;
}else{
last->next=pt;
last=pt;
}
}
// return the size of the list
int LinkedList::size(){
Link* pt(first);
int count(0);
while(pt!=NULL){
count++;
pt=pt->next;
}
return count;
}
// display the content of the list
void LinkedList::display(){
Link* pt(first);
while(pt!=NULL){
cout<<"["<<pt->num<<"]"; pt=pt->next;
}
cout<<endl; } // overloading operator [] int LinkedList::operator [] (unsigned index){ Link* pt(first); int count(0); while(pt!=NULL){ if (count==index) { return pt->num;
break;
}
count++;
pt=pt->next;
}
if (pt==NULL) return INT_MAX;
}
// return the first element of the list
int LinkedList::front(){
if (first==NULL) return INT_MAX;
return first->num;
}
// return the last element of the list
int LinkedList::back(){
if (last==NULL) return INT_MAX;
return last->num;
}
